Motivation
The challenges facing record linkage in Germany and other regions, highlight the urgent need for solutions that balance data privacy with research utility. There is growing recognition among researchers, policymakers and data custodians that harmonized legal frameworks, standardized technical infrastructures and privacy-preserving technologies are essential for unlocking the full potential of health data.

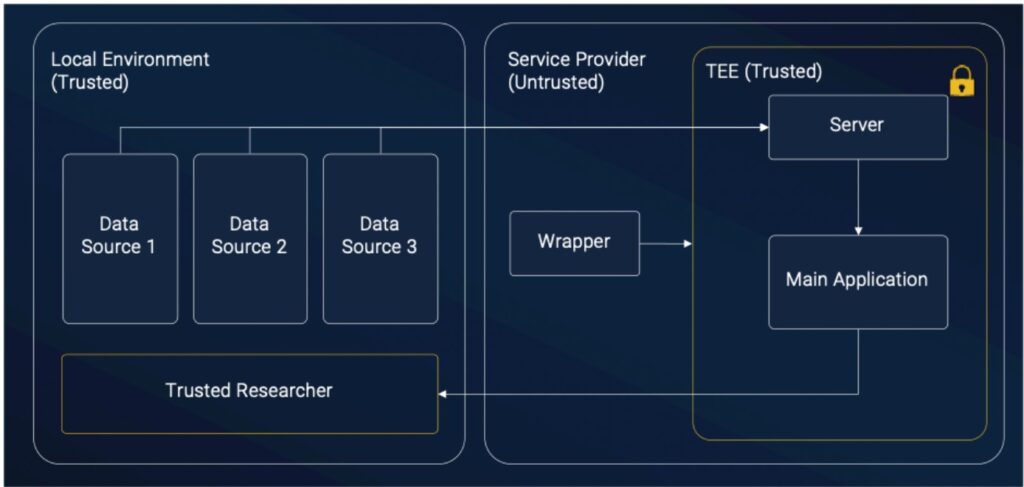
What Is a Trusted Execution Environment (TEE)?
A Trusted Execution Environment, or TEE, is a secure area within a computer’s processor that is isolated from the rest of the system. It allows sensitive data to be processed in a way that prevents access by unauthorized users, even if they have control over the system itself. TEEs offer a strong guarantee that both the computation and the data remain confidential throughout processing and thus help with complying with legal and ethical standards for healthcare data handling.